
前情提要
很多人問我,你是怎麼維持每天都有內容產出的?其實秘訣只有一個:持續的輸入。
在輸入(讀文章、看影片、滑 Threads)的當下,大腦就會自然產生自己的想法。其實每個人每天都會思考很多事情,只是當下我們沒有立馬記錄下來,之後很快就會忘掉。
這套系統強大的地方就在於:它能夠刺激我思考,並在我產生想法的瞬間,透過 AI 自動化流程直接把它轉化成草稿。
我的核心策略:借力權威,內化觀點
作為一個追蹤者(Follower)還不多的新手,我們講的話往往缺乏說服力。所以我選擇的方式是:借用權威人士的內容,再加上自己的觀點。
這不僅讓內容看起來更有權威感,也降低了創作的門檻。
技術架構:7 個關鍵的 n8n 工作流 (下載區)
為了實現 24 小時不間斷的靈感收集,我設計了 7 個核心的 n8n 工作流。
- Feeds (Newspapper)
- Feeds (Instagram)
- Feeds (Threads)
- Feeds (Twitter)
- Feeds (Youtube)
- Content Agent
- Copy Drafter
這些工作流從各大平台抓取內容,並由 AI 進行分析處理。
小應用程式
要讓這套「靈感收割機」轉起來,我們還需要幾個厲害的工具:
- Tiny Tiny RSS (TTRSS):這是我的內容集散地,用來收集 Newspaper, Threads, X, Youtube 的內容。
- Apify:
- Instagram:因為 IG 的 RSS 極其不穩定,我直接用 Apify 抓取。
- Threads/X/YouTube:當 TTRSS 監測到我追蹤的帳號有新內容時,會觸發 Apify 把內容(貼文文字或影片逐字稿)抓出來。
- Whisper:對於 Instagram,我會先用 Apify 抓取音檔,再利用 OpenAI 的 Whisper 模型翻譯成文字。
- Browserless:主要用於 Newspaper,有些網站內容抓不到時,我會用 Browserless 嘗試渲染抓取。
- RSS-HUB:必裝工具,它是許多平台生成 RSS 訂閱源的神器。
把資訊流整合到 Notion:一覽無遺
所有的內容在抓取後,會經過以下自動化處理:
Step 1:AI 自動分類與打標籤
採集到的內容會先經過 AI 分析總結、加上 TAG等等,自動更新到我的 Notion 資料庫。
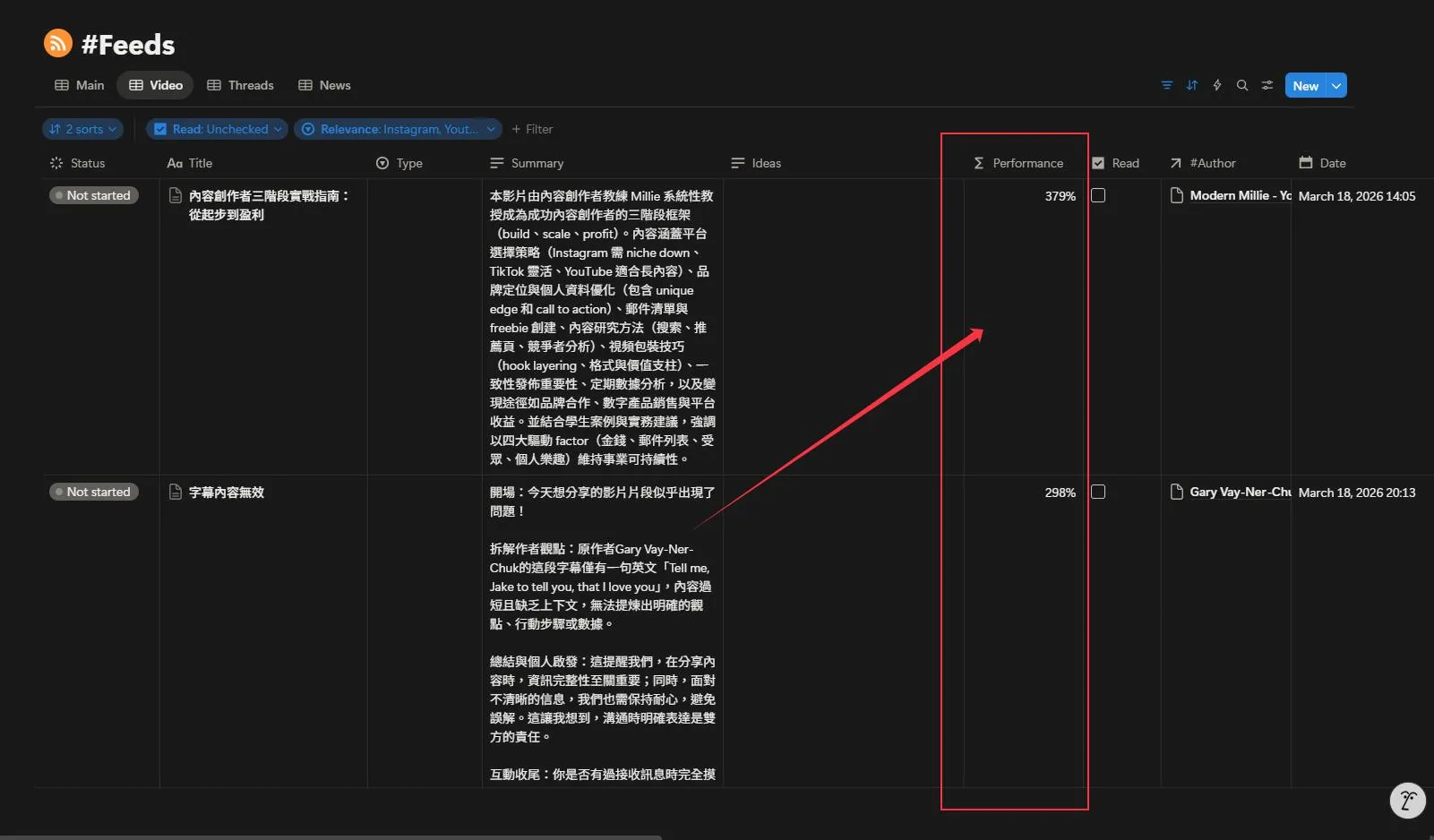
Step 2:Performance 導向的閱讀策略
我每天打開 Notion,會優先看 Performance 數據比較好的內容。例如:圖片中這支影片是高於該創作者平均 Views 數 3 倍有多,那它絕對有值得學習的 Hook 或內容邏輯。
Step 3:一鍵啟動 AI Agent 生成草稿
當我看到一段有啟發的內容,想要利用權威觀點分享時:
- 在 Notion 的
Type欄位選擇我安排好的 AI Agent 風格 Skill。 - 我會把自己一些想法寫在
Ideas欄位(可以不寫) - 在
Read欄位打勾。 - 5 分鐘左右,系統就會自動幫我寫成草稿,並轉移到
# Content。
AI Agent Skill 與 模型設定
這套系統的 AI Agent 風格設定。這些 Skill 我都部署在 Zeabur 上。
使用的 AI 模型推薦
我目前使用的是 Open Router 上的模型,成本極低且穩定:
- 草稿生成:我最近在試用
nvidia/nemotron-3-super-120b-a12b:free - RSS 分析與過濾:我使用免費的
Step 3.5 Flash (free)或Arcee AI: Trinity Large Preview (free)。- 在 Open Router 只要儲值 10 美元,這些免費模型每個月可以打 100 萬次 Request,幾乎等於免費使用。
全手動搭建指南
這套系統雖然強大,但初始設定需要一點耐心。以下我將拆解各個組件的安裝與連結方式。
1. 準備工作:下載資源與 Notion 資料庫設定
這是整個系統的地基,請按照步驟將所需資源準備好。
- 下載 7 個核心工作流:請至 charlsondou 產品頁面 下載這套系統的 7 個 n8n 工作流 Json 檔。
- Notion 範例資料庫:
- 匯入我的 一人公司經營系統 (Template) 範例資料庫到你的 Notion workspace。
- ⚠️ 關鍵步驟:匯入後,
#Feeds與#Author範例資料庫請務必點擊右上角的...選單 ->Add connections,重新連結你之前在 Notion 開發者後台申請的 Integration (API)。 - 至於草稿生成的去向
#ContentDatabase,你可以把我們在「多平台發文系統」那章建立的同一張資料庫的內容轉移到這裡的 #Content (Template)。
2. Tiny Tiny RSS (TTRSS) + RSS-HUB (Zeabur 快速部署)
這兩個工具是系統的「內容集散地」。好消息是,它們都可以在 Zeabur(這是聯盟行銷 + 輸入我的優惠碼享有額外優惠)上一鍵快速部署。
第一步:部署 RSS-HUB
- 在 Zeabur 搜尋 「RSSHub」 並點擊安裝。
- 安裝完成後,你會看到兩個服務:
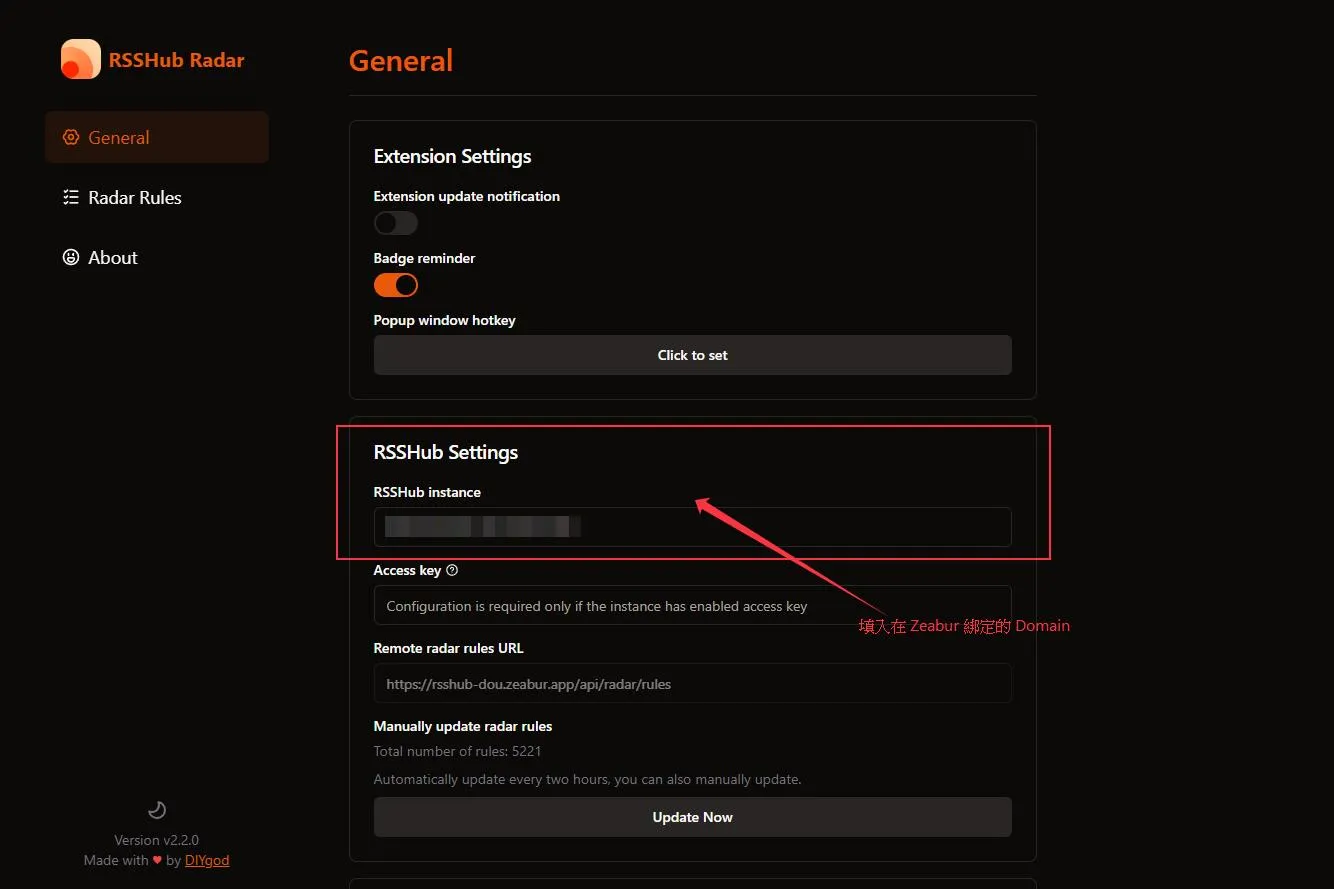
Redis與RSSHub。 - 進入
RSSHub服務,在 Networking標籤頁下方點擊Generate Domain,自訂一個你的專屬網址。 - Radar 助手:在 Chrome 瀏覽器安裝RSSHub Radar 擴充功能,並在 General 設定中填入你剛剛產生的系統網址。以後只要網頁有 RSS 來源,Radar 就會自動偵測。
第二步:部署 Tiny Tiny RSS (TTRSS)
- 同樣在 Zeabur 搜尋 「TinyTinyRSS」 並安裝。
- 安裝後同樣在 Networking 產生一個 Domain,等綁定成功後點擊網址進入 TTRSS 頁面。
- 初次登入:預設帳號為
admin,密碼為password。進去後請立刻到右上角偏好設定 -> 使用者 更改密碼或建立新帳號。
第三步:訂閱與管理 (OPML 匯入)
- 匯入範例:到偏好設定 -> 摘要 -> OPML 匯入我提供給你的 OPML 檔案。匯入後,左側會出現預設的分類與訂閱源。(內含我的訂閱源分享給你)
- 新增與刪除:
- 刪除:在訂閱源點右鍵 -> 編輯摘要 -> 取消訂閱。
- 你可以在每個訂閱源上右鍵 → 編輯摘要 → 參考該連結去新增你需要的帳號
- 新增 (以 YouTube 為例):YouTube 的連結格式通常為
https://{你的rss hub domain}/youtube/user/@{username}。 - 點擊右上角三條橫線 -> 訂閱摘要,貼上網址並選擇對應分類(如:YouTube)即可完成訂閱。
- 下載 OPML 檔案
3. 各核心工作流設定解析
這套系統包含多個不同平台的工作流,我將逐一拆解它們的設定細節。
💡 節點顏色圖例說明:
🟢 需要你手動改動/輸入參數的節點
🔴 系統已經寫好,不需要去動它的節點
3.1 Feeds (Instagram)
這工作流內包含兩條自動化流程:
流程一:每日抓取最新 Reels
這條流程由名為 Instagram-Tools 的 Scheduled Trigger 觸發,設定為每天只執行一次。
- Setting 🟢:請在此節點設定
reels_results_limit與only_posts_newer_than參數。reels_results_limit:我預設為3,代表每天從各帳號抓取最近的 3 支 Reels。如果對方當天發布了 4 支,則只會抓取最新的 3 支。only_posts_newer_than:我預設為1 day,只抓取過去 24 小時內的新影片(你也可以根據需求調整為更長的時間)。
- Get Data (Author) 🔴:到 Notion 的
#Author資料庫中,找出我登記的創作者。(這個節點只需要確認有正確指向 Notion 的 #Author Database 即可)- *設定要件 *:在 Notion 中,只需確保
Platform欄位為Instagram,且Link欄位貼上他們 IG 主頁的連結(注意:最後不要有斜線/)。第一次執行成功後,其他欄位 n8n 會自動補齊。
- *設定要件 *:在 Notion 中,只需確保
- Aggregate & Build Json 🔴:將取出的 IG 連結聚合成一包,並轉換為適合 Apify 接收的格式。
- Instagram Scraper 🔴:呼叫 Apify 爬取這些帳號在過去 24 小時內發佈的 Reels。
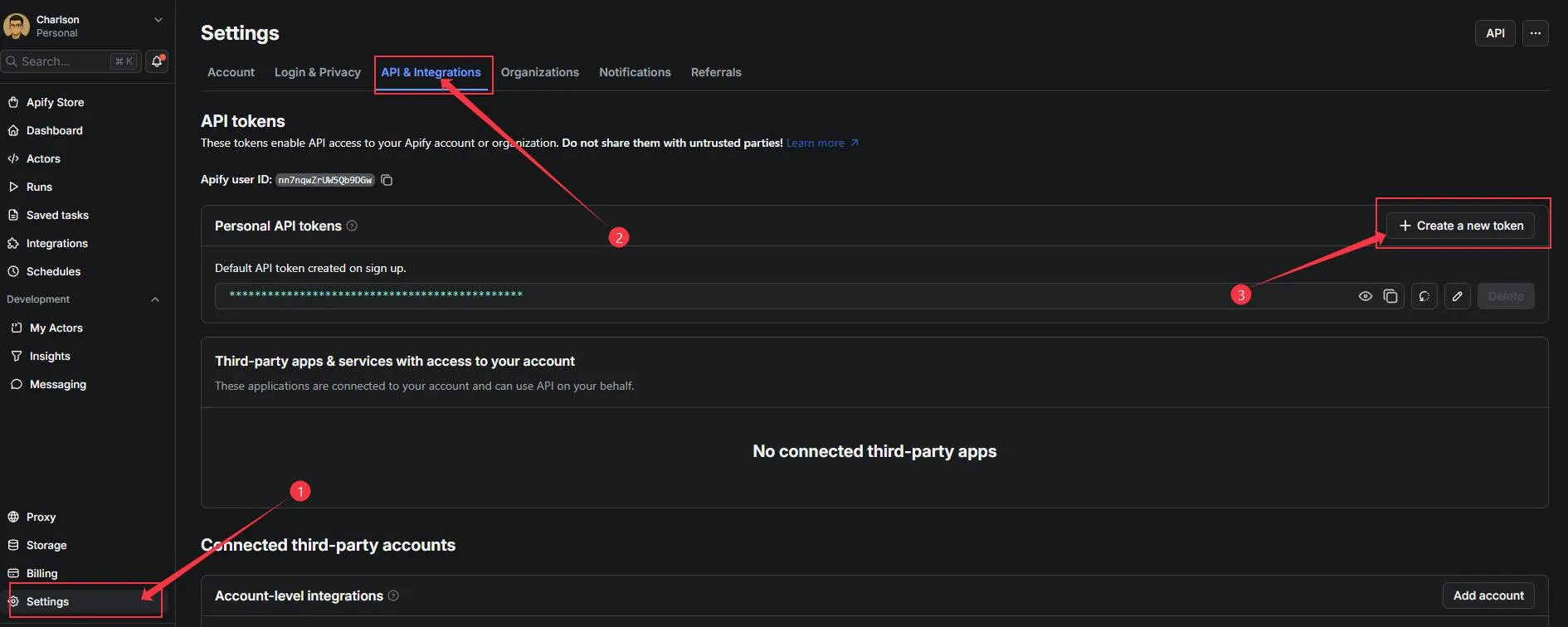
- 設定 API Key:前往 Apify(這是聯盟行銷連結)→ Console -> Settings -> API & Integrations -> Create a new token。回到 n8n,在該節點新增 Credential 並貼上 Token,其他設定保持預設即可。
- 費用提醒 :Apify 每月有 5美元的免費額度。此InstagramScraperActor 的計費方式約為2.7 美元 / 1000 筆結果。
- No Post? In Pinned? 🔴:過濾機制,把帳號的「置頂影片」排除掉,避免重複抓取舊資料。
- Loop Over Items & Download 🔴:將抓到的影片清單一一拆解,並實際下載影片檔案。
- Whisper 🔴:將下載的影片聲音轉換成文字。
- 設定 API Key:你需要去 OpenAI 申請 API Key。在該節點的 Header Auth 新增 Credential,
Name設為Authorization,Value設為Bearer {你的 OPENAI API KEY}。
- 設定 API Key:你需要去 OpenAI 申請 API Key。在該節點的 Header Auth 新增 Credential,
- Basic LLM Chain (AI Agent)🔴:利用 AI 分析逐字稿,輸出
Title、Summary及Category。- 這裡同樣使用 OpenRouter 的免費模型(如
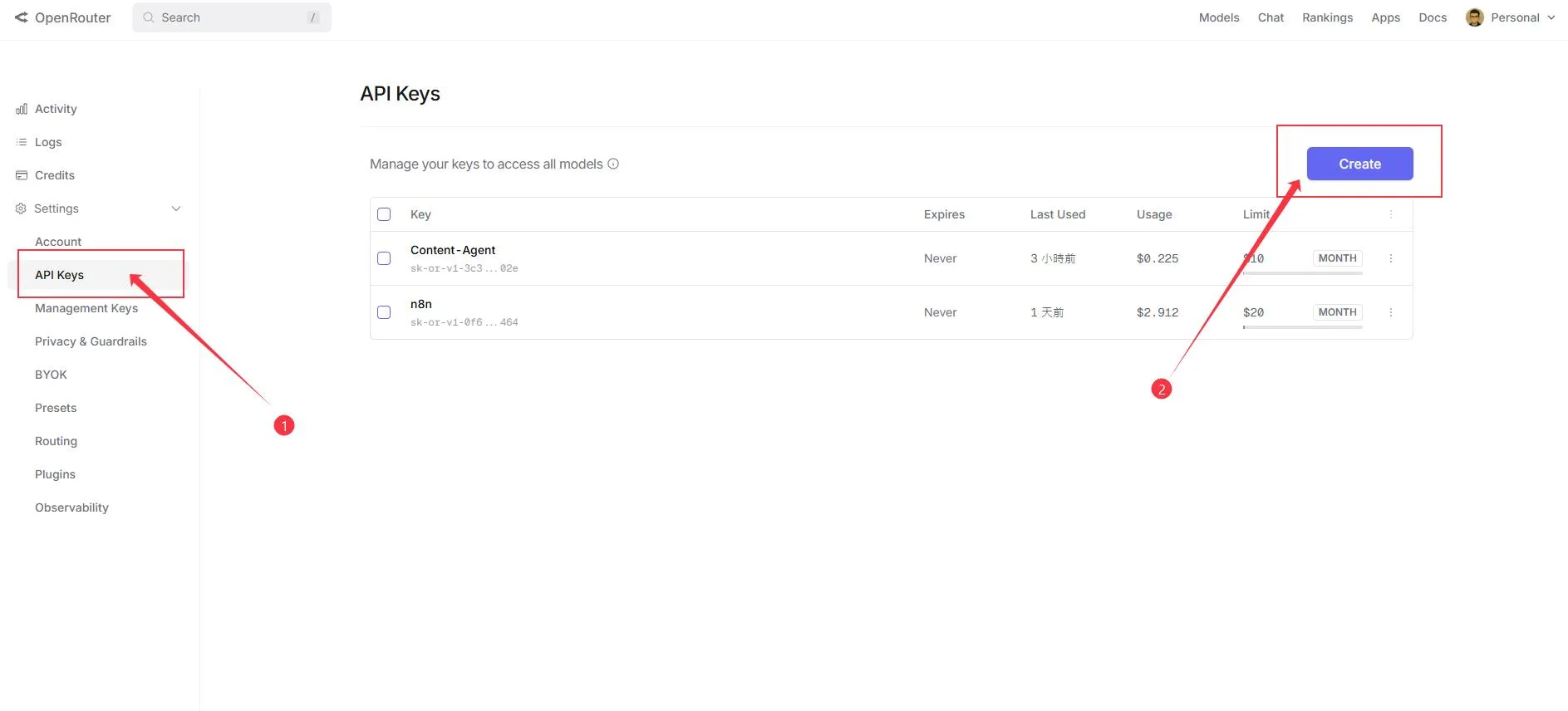
StepFun: Step 3.5 Flash或Arcee AI: Trinity)。 - 設定 API Key:在
OpenRouter Chat Model節點新增一個 Credential 填入 OpenRouter API Key。推薦使用免費的StepFun: Step 3.5 Flash或Arcee AI: Trinity Large Preview。
- 這裡同樣使用 OpenRouter 的免費模型(如
- Chunk Caption & Chunk Block 🔴:檢查 AI 輸出的 Summary 或原文是否超過 2000 字(Notion 單一 Block 的上限)。若超過,會自動切段處理。
- Notion 資料庫聯動邏輯:
- Get Author ID 🔴:檢查 Notion 是否已存在該作者連結,決定後續動作。
- Add Page (Feeds) 🔴:若作者已存在,直接把新影片內容存入
#Feeds。 - Create ID (Author) / Create Page (Feeds) 🔴:若作者不存在(通常不會發生,因為這是手動建的),會先建立 Author 再建立 Feeds。
- Update (Author) 🔴:最後,將這篇新建的 Feed 關聯回該 Author 頁面,為未來的創作者數據分析做準備。
流程二:Instagram CLV Counter (歷史數據更新)
這是一條輔助流程,同樣每天執行一次。
- 功能:它會專門回溯過去2 天 的 Reels,重新抓取並更新 Likes, Views, Comments 等互動數據。
- 目的:社群內容發佈後 48 小時內數據變化較為準確,這更新能讓我們更準確地分析該創作者的內容成效。
💡 小撇步:如果你想回溯更久以前的數據,只需在Get Data (Feeds)1 節點中,將
Date欄位的On Or After設為:{{ $now.minus({ days: 2 }).toISO() }},並將其中的2改為 3、10 或 20 等天數即可。但請注意,回溯天數越多,Apify 的爬取費用也會隨之增加。
3.2 Feeds (Newspapper)
這是抓取 RSS 新聞核心的邏輯:
- Business RSS 🔴:這是一個 Scheduled Trigger,設定為每 15 分鐘檢查一次 TTRSS 是否有更新。
- Setting 🟢:請在此節點輸入以下必要資訊:
ttrss_login_username={你的 ttrss 帳號名}ttrss_login_password={你的 ttrss 密碼}ttrss_endpoint_url=https://{你的 ttrss domain}/api/ttrss_feed_id={該分類 ID}(💡如何拿分類 ID:先輸入好帳號密碼與 Endpoint 後手動執行一次,在後面Session ID節點的 Output data 中,每個標題上方就會顯示該分類的 ID。)。browserless_endpoint_url=https://{你的 domain}/scrapebrowserless_token={輸入 Zeabur Overview 顯示的 Token}
- Login 🔴:登入你的 TTRSS 系統,此節點不需要修改。
- Session ID 🔴:取得暫存憑證,其 Output data 中在每個標題上方會顯示該分類的 ID。
- Get Headlines 🔴:利用剛剛取得的 Session 抓取未讀文章。
- Split Out & Loop Over Items 🔴:將抓到的一大包資料拆分,並一個一個往下傳送。
- Get Article 🔴:抓出單一 RSS 節點的文章全文內容。
- Use Browserless? 🔴 (條件判斷):有些網站 TTRSS 抓不到資料,我在這裡設定了 Regex 比對
{我需要用 Browserless 的網站名}(例如 CNET、Young Upstarts 等)。如果你新增了抓不到資料的來源,請更新這個節點的 Conditions。- Yes (需要 Browserless)
->Get Article2 🔴:向你的 Browserless 伺服器發送請求。(如果你還沒安裝,同樣可以在 Zeabur 快速部署 Browserless,在 Zeabyr 搜尋 Browserless 並點擊快速部署即可,完成後在 Networking 綁定 Domain,然後在 n8n 的 Setting 節點的 browserless_endpoint_url 中填入 https://{你的 domain}/scrape。),browserless_token 剛是 Zeabur 該 Browserless 專案 Overview 裡面看到的 Token。) 如果不成功,則進入 Get Article2 🔴 將該文章標示為已讀,跳過處理。 - No (直接成功)
->To Markdown 🔴:將 HTML 轉為 Markdown,讓 AI 更容易閱讀。
- Yes (需要 Browserless)
- Information Extractor 🔴 (AI Agent):重點節點!負責產出1. 總結、2. 標題、3. 分類。
- 設定 API Key:在
OpenRouter Chat Model節點新增一個 Credential 填入 OpenRouter API Key。推薦使用免費的StepFun: Step 3.5 Flash或Arcee AI: Trinity Large Preview。
- 設定 API Key:在
- Update Article 🔴:完成讀取後,回到 TTRSS 將該文標記為已讀。
- Json Success? 🔴:防呆機制,檢查 AI 是否成功產出。
- Chunk Caption & Chunk Block 🔴:若 AI 總結或原文超過 2000 字(Notion 單一 Block 上限),自動切段。
- Create Feeds 🔴:最終摘要建立到 Notion 的
#Feeds(這個節點只需要確認有正確指向 #Feeds Database 即可)。
3.3 Feeds (YouTube, Threads, Twitter)
這三個平台的工作流與 IG 最大的不同在於:它們是透過 TTRSS 作為中繼站的。因為 TTRSS 本身具備「過濾已讀訊息」的功能,所以就算 Scheduled Trigger 設定為每 1 小時抓取一次,也絕對不會重複抓到同一篇內容。
以下我們以 Feeds (YouTube) 為例來拆解:
- Scheduled Trigger 🔴:設定為每小時執行一次。
- Setting 🟢:請在此節點輸入以下必要資訊:
ttrss_login_username={你的 ttrss 帳號名}ttrss_login_password={你的 ttrss 密碼}ttrss_endpoint_url=https://{你的 ttrss domain}/api/ttrss_feed_id={該分類 id}(💡如何拿分類 ID:先輸入好帳號密碼與 Endpoint 後手動執行一次,在Session ID節點的 Output data 中,每個標題上方就會顯示該分類的 ID。)。email={你的 email}
- Login 🔴:登入你的 TTRSS 系統。
- Session ID 🔴:取得暫存憑證,其 Output data 中在每個標題上方會顯示該分類的 ID。
- Get Headlines 🔴:利用剛剛取得的 Session 抓取未讀文章。
- Split Out & Loop Over Items 🔴:將抓到的一大包資料拆分,並一個一個往下傳送。
- Get Article 🔴:抓出單一 RSS 節點的文章全文內容。
- Get Video CLV 🔴:這是一個 Google HTTP Request 節點,用來抓取影片的 Likes、Views、Comments 等互動數據。
- 注意:這裡不需要使用付費的 Apify,因為 YouTube 官方就有提供 API。你只需要設定好 OAuth2 API 即可(詳細教學可參考:Google OAuth 憑證申請指南)。
- Switch 🔴:過濾機制。有些創作者會發布僅限「頻道會員」觀看的優先影片,這個節點會把這些一般人還看不到的影片擋下來。
- Youtube Transcript 🔴:利用 Apify Actor 抓取這部 YouTube 影片的 CC 字幕(這組 Actor 的計費方式約為 $10 美元 / 1000 筆結果)。
- Empty Content? 🔴 (條件判斷):檢查有沒有成功抓到字幕。
- True (抓不到字幕 / Apify 出錯)
-> 進入Send a message🔴 節點:透過 Gmail 發送錯誤通知給我們自己提醒我們 Apify 可能出錯了。接著進入Update Article🔴 提早將該 RSS 標記為已讀,避免 n8n 無限迴圈重試。 - False (成功抓取)
-> 順利進入To Markdown🔴 節點,將內容轉換成 AI 好讀的格式。
- True (抓不到字幕 / Apify 出錯)
- 後半段處理:接下來的
Basic LLM Chain(呼叫 Open Router 產出標題、總結、分類)、Chunk Caption、Chunk Block,一直到寫入 Notion 資料庫的驗證(Get Author ID、Add Page等),整套邏輯與 IG 工作流一模一樣。
流程二:Youtube CLV Counter (歷史數據更新)
這是一條輔助流程,同樣每天執行一次。
- 功能:它會專門回溯過去2 天 的影片,重新抓取並更新 Likes, Views, Comments 等互動數據。
- 目的:社群內容發布後 48 小時內數據變化最大,持續追蹤能讓我們更準確地分析該創作者的內容成效。
💡 小撇步:如果你想回溯更久以前的數據,只需在Get Data (Feeds) 節點中,將
Date欄位的On Or After設為:{{ $now.minus({ days: 2 }).toISO() }},並將其中的2改為 3、10 或 20 等天數即可。但請注意,回溯天數越多,Apify 的爬取費用也會隨之增加。
新增追蹤對象的邏輯差異:
- Instagram:由於 IG RSS 極不穩定,若要追蹤新帳號,請直接到 Notion 的
#Author資料庫中新增資料(填寫 Link 與 Platform)。 - YouTube、Twitter (X)、Threads:這三者我們是透過 TTRSS 穩定管理的,若要追蹤新帳號,你必須在 TTRSS 網頁端新增訂閱源,千萬不要跑到 Notion 裡去加。
3.4 Content Agent (觸發 AI 寫手 & Zeabur 部署邏輯)
這支工作流負責將你過濾並挑選好的素材送到 AI 面前。
- Scheduled Trigger:設定為每 5 分鐘執行一次。它會去掃描 Notion 的
#Feeds資料庫。- 觸發條件:當你把一篇文章的
Read打勾、Type選擇了想要的 AI Agent 風格、且Status是Not Started時,這筆資料才會被抓出來。
- 觸發條件:當你把一篇文章的
- Loop Over Items -> Get Child Blocks -> Aggregate:一筆一筆將原本的圖文內容抓出並合併。
- Send to Content-Agent (核心 API 呼叫):將合併好的資料,打 API 到你部署在 Zeabur 上的 Content Agent 專案 (
https://{你的 content agent 專案 domain}/api/generate)。
部署 Content Agent 到 Zeabur 步驟:
- 前往 GitHub 下載我的 Content Agent 專案 到你的電腦下。
- 路徑 Content-Agent/author_dna 裡,把 Notion #Content 發佈過的貼文匯出成 csv 檔案放進來。
- 放上你的 Github 帳號。
- 在 Zeabur 綁定你的 GitHub,並選擇這個剛放好的專案進行部署。建立完成後,在 Networking 分頁產生一組 Domain。
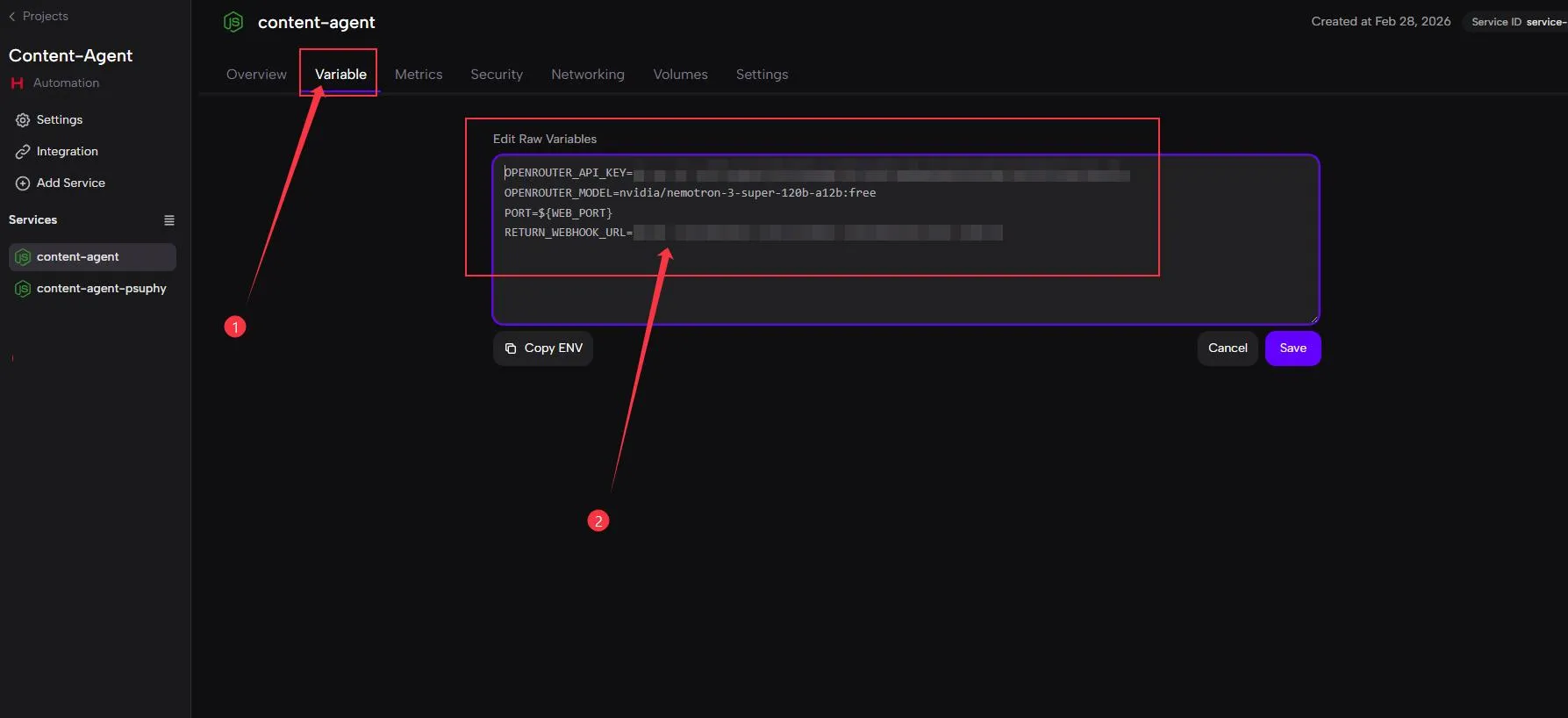
- 設定環境變數:進入 Zeabur 專案 -> Variable -> Edit Raw Variables,填入以下資訊:
OPENROUTER_API_KEY={你的_OpenRouter_API_KEY}OPENROUTER_MODEL={你的_OpenRouter_Model}(我最近是用 nvidia/nemotron-3-super-120b-a12b:free)RETURN_WEBHOOK_URL=https://{你的_n8n_domain}/webhook/copy-drafter(這是稍後 Copy Drafter 工作流的 Webhook 網址)PORT=3000
**💡 作者理念分享:為什麼我不做「全自動」發佈?**系統會根據你
Type所選的 Agent Skills (Prompt) 來生成草稿。但我一再重申:AI 的作用是「協助」。
就算今天 AI 寫出來的貼文「毫無 AI 味」,我依然不會直接發佈。因為太過依賴 AI 會極快地降低我們自身的表達能力與思考深度。我不希望自己變成一個在網路上侃侃而談,線下見面卻毫無靈魂的人。除非我在做的是「矩陣帳號」(帳號人設不代表我本人),才會 100% 全自動化。
3.5 Copy Drafter (自動建立草稿)
這支工作流負責接收 Zeabur 上 AI 寫手產出的文章,並寫回 Notion。
- Webhook 節點:這是觸發點,負責接收 Content Agent 處理完畢打回來的資料。
- 路徑設定:預設 Path 是
copy-drafter。這就是前面 ZeaburRETURN_WEBHOOK_URL填寫的目標網址 (記得是 Production URL)。 - 收到的
body會包含notion_id以及生成的results草稿等資訊。
- 路徑設定:預設 Path 是
- Get Data (Feed) -> Get Child Blocks -> Aggregate:利用傳回來的
notion_id,去 Notion#Feeds找回當初的那篇素材原文,並將原文擷取合併。 - Chunk Block 節點:為符合 Notion API 單一區塊字數限制,將長篇草稿切段。
- Create Content 節點:最後,在我們的
#Content資料庫(也就是我們多平台發文系統共用的那張核心資料庫)中,自動建立一筆新的草稿。- 我預設勾選了發布到四個平台:
["Threads", "Facebook", "LinkedIn", "Discord"]。你可以在這個節點的 Platform 欄位依據個人需求自行更改。
- 我預設勾選了發布到四個平台:
總結
這套自媒體管理系統 4.1 章的設計初衷,是為了讓創作者從瑣碎的「找素材」中解脫出來。
不再需要每天對著空白螢幕發愁,而是讓整個互聯網成為你的墨水瓶。
記住:保持輸入,保持思考,剩下的交給自動化。
👉 加入自動化社群
如果你對這套系統感興趣,或者在嘗試搭建的過程中遇到問題,
歡迎 加入我的 Discord 社群,有任何卡關的地方,都可以直接在群裡找我。
付費會員會有一個專屬的私人頻道,你可以在那裡直接告訴我你在自動化過程中遇到的痛點。
如果這是一個大家都有的需求,我會親自開發解決方案,並把它整合進系統裡。
讓我們一起把它變得更強大。


