
⚡ 快讀摘要
- 核心痛點:RSS 分類與關鍵字過濾太死板,滑完一圈常無收穫,白白浪費寶貴時間。
- 解法路徑:利用 AI Agent 進行「智能判斷」與「精準評分」,只推播高分精華。
- 技術架構:Tiny Tiny RSS (採集) + Supabase (記憶) + News Reporter (介面)。
- 部署關鍵:在 Zeabur 一鍵部署後,設定正確的環境變數與 SQL 腳本即可啟用。
你是不是常常打開新聞 / 資訊 App,滿心期待的想吸收新知識,結果滑了滑,又再滑了滑,一直沒看到自己感興趣的資訊,就這樣 1 小時過去了,今天好像什麼都沒吸收到。
以前為了改善這個問題,我們會利用 RSS 訂閱源,分門別類不同資訊,甚至加上不同的關鍵字,目的是盡可能提早排除掉自己不感興趣的資訊。
例如我會分成:
- 科技
- AI
- 財經
- 創業
- 等等…
但不知道你有沒有跟我一樣的感受,就算分門別類了,效果跟理想中的還是有一段蠻大的差距。
拿「科技」這個類別舉例,太空、汽車、機器人等等都屬於科技,但如果我對汽車不感興趣,每次看到也只能默默滑過。有時候滑到累了悶了,還是沒有看到自己感興趣的資訊,完全沒有收穫的感覺,超級吶悶的。
我一直在想,進入 AI 新人類時代的我們,是否應該有更好的資訊吸收方式呢?
如果有一個 「AI Agent」,它就像我的私人秘書,「記得我的偏好」,每天先幫我看好所有資訊內容,然後把它認為我會喜歡的內容「剪」下來,直接放到我的桌面上呢?
為什麼「分類」與「關鍵字」不夠用?
以前我們靠關鍵字過濾,但說實話,關鍵字這東西有點死板。
AI 就不一樣了,它是「活」的,透過記憶與理解,它能做到一定程度上的自主彈性。
傳統過濾方式 (死板)
- 依賴固定關鍵字,容易錯過同義詞
- 分類過於粗糙,細分操作不夠靈活
- 無反饋機制,系統永遠不會變聰明
AI 自家新聞台 (智能)
- 語境理解,判斷文章是否符合你的關注點
- 1-10 分精準評分,直擊資訊密度最高處
- 反饋進化,愈吐槽 AI 愈懂你的心
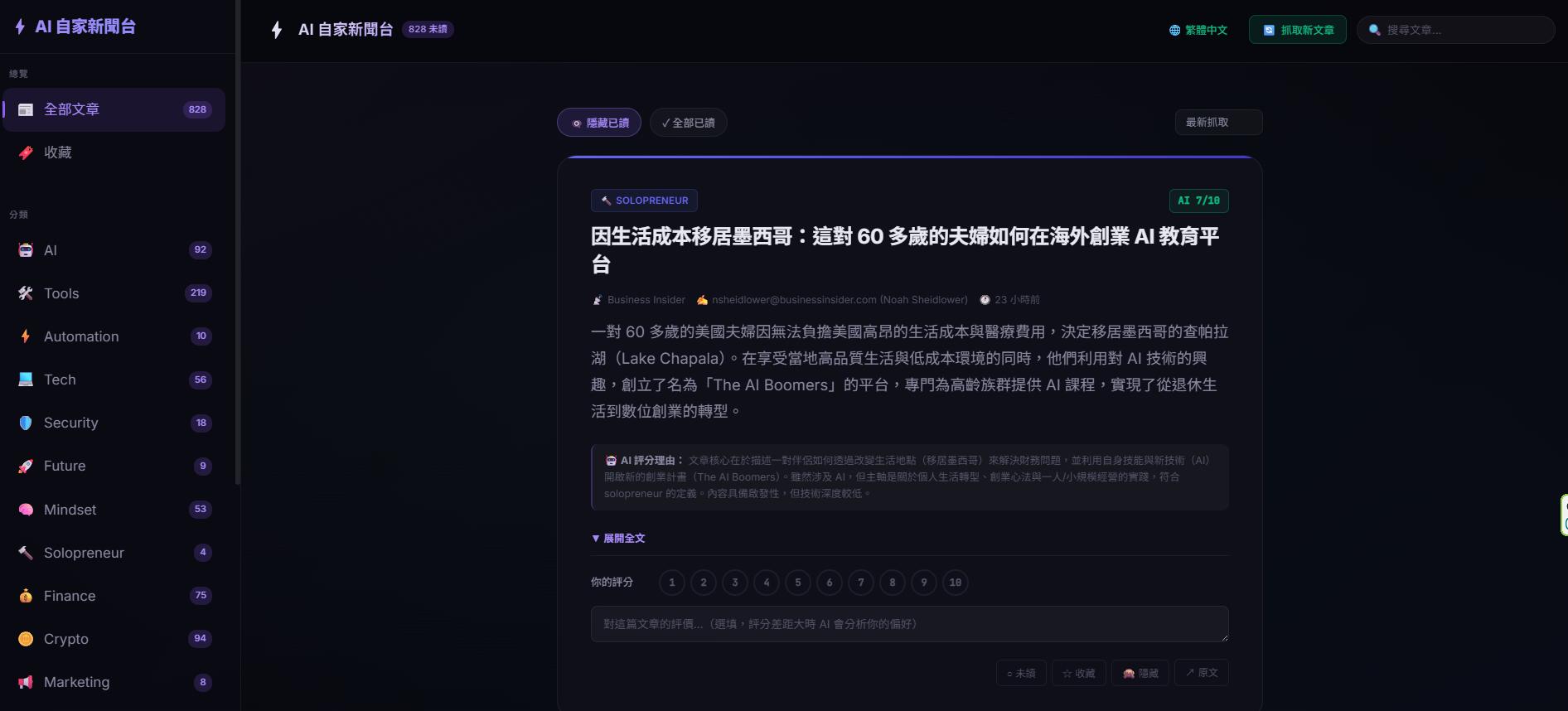
「AI 自家新聞台」呈上來的內容,每一則都會經過它的「思考」。
它會根據我的歷史反饋,去判斷為什麼這篇內容適合我,把推薦的原因記錄下來,並且打上 1 到 10 的推薦分數。
舉個例,當系統抓到一則關於「Tesla」的新聞時,傳統過濾器會因為它帶有「科技」標籤就一股腦塞給我。
但 AI 會幫我過濾掉噪音:
「老闆最近在研究的是 AI 落地應用,這篇 Tesla 新聞講的只是硬體工廠的產能規劃,對他目前的思考沒有直接幫助,打 4 分就好了,先不推薦他看。」
而當中為什麼它會知道我在研究 AI 落地應用呢?
因為之前的每篇文章我都可以給它反饋,例如留言說:「這篇我不喜歡,因為我對 AI 落地應用比較感興趣」,它就會把我的反饋記錄下來,作為未來判斷的依據。
這種能先被「理解」才推薦的感覺,我想才是 AI 新時代我們新人類生活的資訊吸收方式吧。
架構:這套系統是如何運作的?
這套系統由三個部分串聯而成:
Tiny Tiny RSS
全天候巡邏並抓取各大訂閱源的原始資料。
Supabase
儲存所有文章、評分歷史與個人偏好知識庫。
News Reporter
負責 AI 評分邏輯處理與介面呈現。
💡簡單來說:TTRSS 負責抓取,Supabase 負責紀錄,News Reporter 則是把結果呈現給你的門面。
快速安裝指南
如果你也想打造一組自己的新聞台,目前我已經將其優化到可以在 「雲端伺服器」 上簡單部署。
安裝步驟摘要
- TinyTinyRSS:Zeabur 搜尋一鍵部署 -> 設定 Networking -> 輸入 RSS 訂閱源。
- Supabase:Zeabur 搜尋一鍵部署 -> 設定 Networking -> 建立資料庫表格。
- News Reporter:複製專案 GitHub Repo -> Zeabur 安裝 -> 設定環境變數。
💡 關於「雲端伺服器」,可以透過我的邀請碼註冊 Zeabur,會享有額外優惠喔!歡迎到他們的官網了解最新優惠。
Zeabur 邀請碼:charlsondou
詳細安裝步驟
第一步:部署 Tiny Tiny RSS (採集端)
- 在 Zeabur 開一個新專案,搜尋 TinyTinyRSS 一鍵快速部署。
- 進入 Networking,點擊
Public -> Generate Domain自訂一個網域。 - 登入 TinyTinyRSS(預設帳號:
admin,密碼:password)。 - 安全性建議:到
偏好設定 (Preferences)->使用者 (Users)-> 點擊admin更改密碼。 - 下載我準備好的 OPML 檔案,到
摘要 (Feeds)->OPML進行匯入。
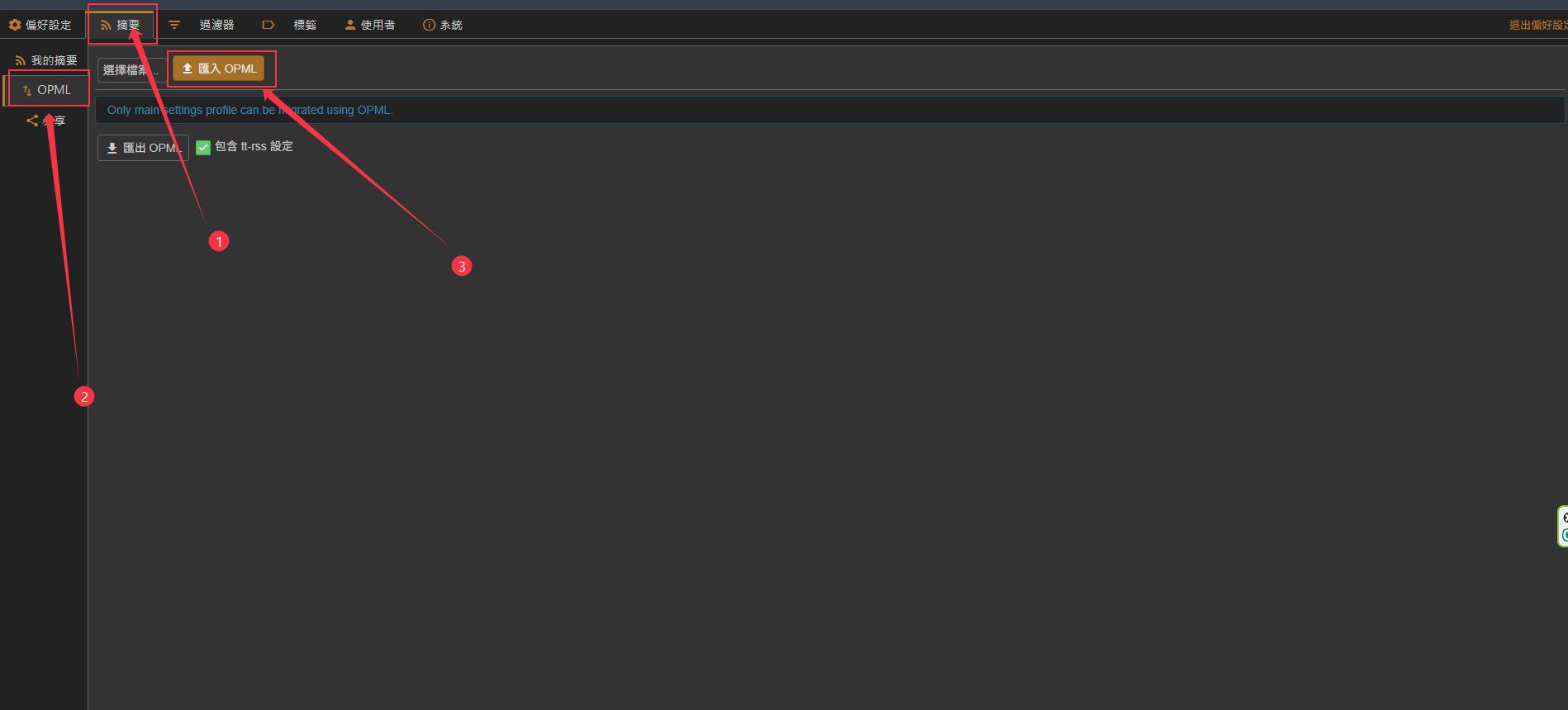
💡OPML 檔案包含了我平時會看的科技、財經、AI、Crypto 等領域的 RSS 訂閱源。
請記下 TTRSS 的 Domain 網址,第三步設定時會用到。
第二步:部署 Supabase (資料庫)
- 搜尋 Supabase 一鍵快速部署。
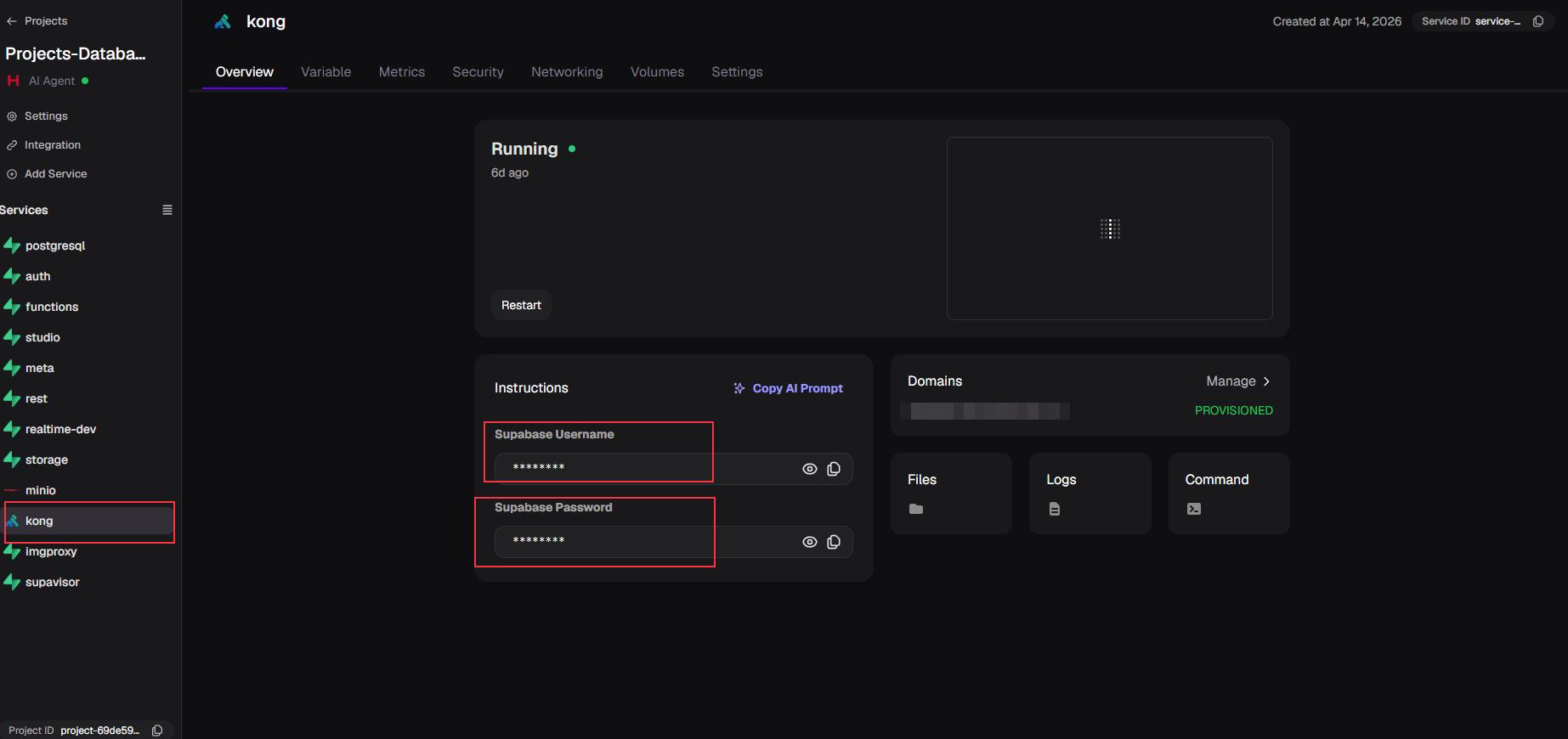
- 在 Kong Service 進入
Networking,Public -> Generate Domain自訂一個網域。 - 登入 Supabase(帳號密碼可在 Kong 的 Overview 中找到)。
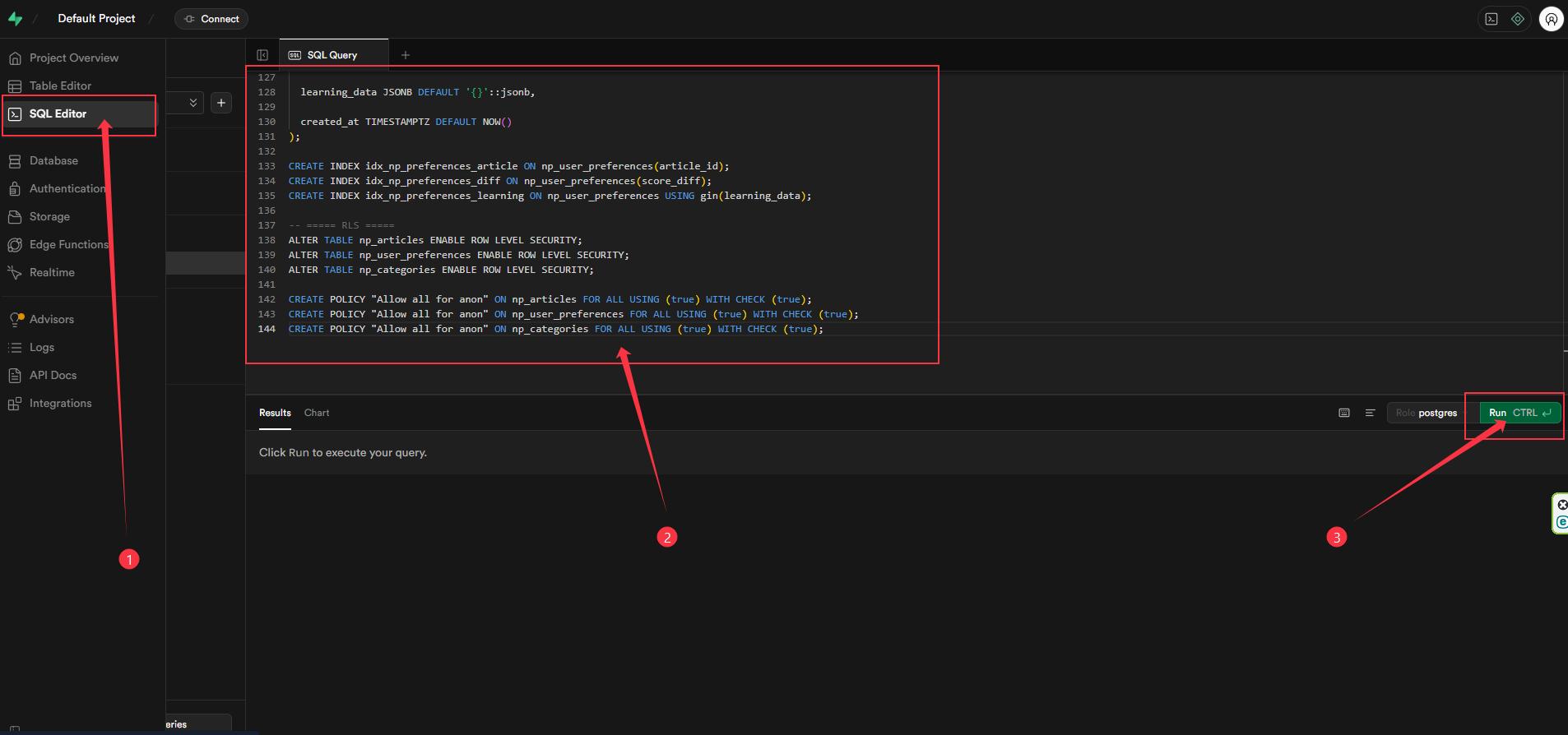
- 進入 SQL Editor,下載我準備好的 SQL 範例。
- SQL 範例是一個 txt 檔案,把裡面的內容複製貼上到 SQL Editor 中。
- 點擊
Run,完成後可以在Table Editor看到相關表格已建立。
請記下 Supabase 的 Domain,以及 Variables 中的 Service Role Key 與 Anon Key。
第三步:部署 News Reporter (介面與邏輯)
- 先將 News Reporter Repo 複製專案 (Fork) 到自己的 GitHub。
- 在 Zeabur 選擇從 GitHub 安裝該專案並設定 Networking。
- 設定以下環境變數 (Environment Variables):
# ===== Tiny Tiny RSS 設定 =====
TTRSS_ENDPOINT_URL=https://your-ttrss-instance.app/api/
TTRSS_USERNAME=admin
TTRSS_PASSWORD=your_password
TTRSS_FEED_ID=-4 # 可選,預設為 -4 表示所有文章
# ===== Supabase 設定 =====
NEXT_PUBLIC_SUPABASE_URL=https://your-project.supabase.co
NEXT_PUBLIC_SUPABASE_ANON_KEY=your_anon_key
SUPABASE_SERVICE_ROLE_KEY=your_service_role_key
# ===== AI 模型 (OpenRouter) =====
# 建議使用高效且穩定的模型
OPENROUTER_API_KEY=your_openrouter_api_key
OPENROUTER_MODEL=openrouter/free
OPENROUTER_SITE_NAME=news-reporter
# ===== App =====
# 資料保留天數 (超過此天數的文章會被自動刪除)
ARTICLE_RETENTION_DAYS="7d"
# 抓取頻率 (多久抓一次新文章,支援 "4h", "12h", "30m", "daily" 等白話文)
FETCH_INTERVAL_CRON="4h"
# 清理排程 (多久執行一次清理舊資料的動作)
CLEANUP_INTERVAL_CRON="7d"
# 網站存取密碼
SITE_PASSWORD=your_password_here結語
當你完成以上步驟後,你就可以利用網址以及密碼,登入 「AI 自家新聞台」,開始訓練你的 AI 助理,從以前被動接收資訊,到現在主動過濾資訊,它不會因為流量而推播八卦給你,也不會強迫你閱讀你不感興趣的內容。
它唯一的任務,就是讓你減少無意義的雜訊,把時間留給真正有價值的事情上。
我們下一篇文章見!


